本文内容较多,请泡个茶,做好准备!
重要知识点:
Go中没有foreach关键字,但是range 关键字可用于for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。
_ 表示占位,用于替代不使用的变量。数据截取返回的是切片。
切片是一个共享存储结构 ,是引用类型。
slice的len大于cap时,会出发扩容。slice的cap增长是当len在1024之前是双倍增长的,而1024以后则是先增长25%以后再调整这个值为系统需要的最小值,因此这个值是约等于cap + cap/4。
⚡️这是我纯手写的《Go语言入门》,源码+文章,手把手教你入门Go。看了你就会!github.com/GanZhiXiong/go_learning 这个仓库中!
数组 数组的声明
声明指定长度数组,并初始化为默认0值。
声明指定长度数组,同时初始化
1 2 3 4 b := [3 ]int {1 , 2 , 3 } c := [2 ][2 ]int {{1 , 2 }, {3 , 4 }}
声明初始化数组时不写长度
1 a := [...]int {1 , 2 , 3 , 4 , 5 }
遍历数组 上一篇我们学习知道了Go仅支持循环关键字for 。
for循环 1 2 3 for i := 0 ; i < len (a); i++ { t.Log(a[i]) }
foreach循环 虽然Go中没有foreach关键字,但是也可以利用for关键字来实现类型foreach循环。
1 2 3 for index, e := range a { t.Log(index, e) }
需要注意是索引不能省略,但是可以“_”来表示占位,这样就能即使不使用index,也不会报错。
1 2 3 for _, e := range a { t.Log(e) }
下面我用代码来演示for循环和for实现的foreach循环:
11_array_test.go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func TestArrayEach (t *testing.T) a := [3 ]int {1 , 2 , 3 } for i := 0 ; i < len (a); i++ { t.Log(a[i]) } for index, e := range a { t.Log(index, e) } for e := range a { t.Log(e) } for _, e := range a { t.Log(e) } }
数组截取 这个很好理解,请直接代码:
11_array_test.go 1 2 3 4 5 6 7 8 9 10 11 func TestArraySection (t *testing.T) a := [...]int {1 , 2 , 3 , 4 , 5 } t.Log(a, reflect.TypeOf(a)) b := a[1 :2 ] t.Log(b, reflect.TypeOf(b)) t.Log(a[1 :3 ]) t.Log(a[1 :]) t.Log(a[:3 ]) }
1 2 3 4 5 6 7 === RUN TestArraySection 11 _array_test.go :52 : [1 2 3 4 5 ] [5 ]int 11 _array_test.go :56 : [2 ] []int 11 _array_test.go :57 : [2 3 ] []int 11 _array_test.go :58 : [2 3 4 5 ] 11 _array_test.go :59 : [1 2 3 ] --- PASS: TestArraySection (0.00 s)
这里我们需要注意是,数组截取后就变成了slice切片了。
切片 切片也是一个连续存储的数据结构。
切片内部结构 它本质上是一个结构体。
ptr指针:指向连续的存储空间,也就是一个数组。
len 存了多少个元素个数。
cap 即capacity,指可以存多少个元素。指针指向的后端这个数组空间长度,比如5个元素的数组,这个cap可以是5。
概念似乎很难理解,下面我用代码来讲解怎么创建切片以及len和cap的区别:
11_slice_test.go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func TestSliceInit (t *testing.T) var s0 []int t.Log(s0, len (s0), cap (s0)) s0 = append (s0, 1 ) t.Log(s0, len (s0), cap (s0)) t.Log("\r" ) s1 := []int {1 , 2 , 3 , 4 } t.Log(s1, len (s1), cap (s1)) s1 = append (s1, 5 ) t.Log(s1, len (s1), cap (s1)) t.Log("\r" ) s2 := make ([]int , 3 , 3 ) t.Log(s2, len (s2), cap (s2)) for i := 0 ; i < 10 ; i++ { s2 = append (s2, i) t.Log(s2, len (s2), cap (s2)) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 === RUN TestSliceInit 11 _slice_test.go :8 : [] 0 0 11 _slice_test.go :10 : [1 ] 1 1 11 _slice_test.go :11 : 11 _slice_test.go :15 : [1 2 3 4 ] 4 4 11 _slice_test.go :17 : [1 2 3 4 5 ] 5 8 11 _slice_test.go :18 : 11 _slice_test.go :24 : [0 0 0 ] 3 3 11 _slice_test.go :30 : [0 0 0 0 ] 4 6 11 _slice_test.go :30 : [0 0 0 0 1 ] 5 6 11 _slice_test.go :30 : [0 0 0 0 1 2 ] 6 6 11 _slice_test.go :30 : [0 0 0 0 1 2 3 ] 7 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 ] 8 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 5 ] 9 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 5 6 ] 10 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 5 6 7 ] 11 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 5 6 7 8 ] 12 12 11 _slice_test.go :30 : [0 0 0 0 1 2 3 4 5 6 7 8 9 ] 13 24 --- PASS: TestSliceInit (0.00 s)
从上面的代码的输出结果可以得出:
len为0,capacity也为0; 初始化后的切片,capacity等于len capacity必须大于或等于len; 如果len增长了,capacity不一定增长; 如果存放不下了元素,capacity则会以2倍增长。
下面用代码再演示下:
11_slice_test.go 1 2 3 4 5 6 7 func TestSliceGrowing (t *testing.T) s := []int {} for i := 0 ; i < 10 ; i++ { s = append (s, i) t.Log(s, len (s), cap (s)) } }
1 2 3 4 5 6 7 8 9 10 11 12 === RUN TestSliceGrowing 11 _slice_test.go :38 : [0 ] 1 1 11 _slice_test.go :38 : [0 1 ] 2 2 11 _slice_test.go :38 : [0 1 2 ] 3 4 11 _slice_test.go :38 : [0 1 2 3 ] 4 4 11 _slice_test.go :38 : [0 1 2 3 4 ] 5 8 11 _slice_test.go :38 : [0 1 2 3 4 5 ] 6 8 11 _slice_test.go :38 : [0 1 2 3 4 5 6 ] 7 8 11 _slice_test.go :38 : [0 1 2 3 4 5 6 7 ] 8 8 11 _slice_test.go :38 : [0 1 2 3 4 5 6 7 8 ] 9 16 11 _slice_test.go :38 : [0 1 2 3 4 5 6 7 8 9 ] 10 16 --- PASS: TestSliceGrowing (0.00 s)
不知你们有没有想过这样一个问题:
capacity增长规则 11_slice_test.go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 func TestSliceCapGrowthRules (t *testing.T) s := make ([]int , 0 ) n := 0 for n < 1500 { s = append (s, n) t.Log(color.White, len (s), cap (s)) if len (s)+1 > cap (s) { t.Log(color.Red, "下一个append将扩容" ) } n++ } }
下面的输出,capacity是2倍增长,符合上一节的总结。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 === RUN TestSliceCapGrowthRules 11 _slice_test.go :54 : 1 1 11 _slice_test.go :56 : 下一个append 将扩容 11 _slice_test.go :54 : 2 2 11 _slice_test.go :56 : 下一个append 将扩容 11 _slice_test.go :54 : 3 4 11 _slice_test.go :54 : 4 4 11 _slice_test.go :56 : 下一个append 将扩容 11 _slice_test.go :54 : 5 8 11 _slice_test.go :54 : 6 8 11 _slice_test.go :54 : 7 8 11 _slice_test.go :54 : 8 8 11 _slice_test.go :56 : 下一个append 将扩容 11 _slice_test.go :54 : 9 16 11 _slice_test.go :54 : 10 16 11 _slice_test.go :54 : 11 16 11 _slice_test.go :54 : 12 16 11 _slice_test.go :54 : 13 16 11 _slice_test.go :54 : 14 16 11 _slice_test.go :54 : 15 16 11 _slice_test.go :54 : 16 16 11 _slice_test.go :56 : 下一个append 将扩容 11 _slice_test.go :54 : 17 32 11 _slice_test.go :54 : 18 32 11 _slice_test.go :54 : 19 32 11 _slice_test.go :54 : 20 32 ...
但是当len大于1024的时候,capacity却变成了1280,不是两倍增长了。
1 2 3 4 5 6 7 8 9 10 11 12 11 _slice_test.go :54 : 1020 1024 11 _slice_test.go :54 : 1021 1024 11 _slice_test.go :54 : 1022 1024 11 _slice_test.go :54 : 1023 1024 11 _slice_test.go :54 : 1024 1024 11 _slice_test.go :56 : 下一个append 将扩容11 _slice_test.go :54 : 1025 1280 11 _slice_test.go :54 : 1026 1280 11 _slice_test.go :54 : 1027 1280 11 _slice_test.go :54 : 1028 1280 11 _slice_test.go :54 : 1029 1280 11 _slice_test.go :54 : 1030 1280
看来得看下Go的源码了。$GOROOT/src/runtime/slice.go,在growslice函数可以看到计算 newcap的算法。
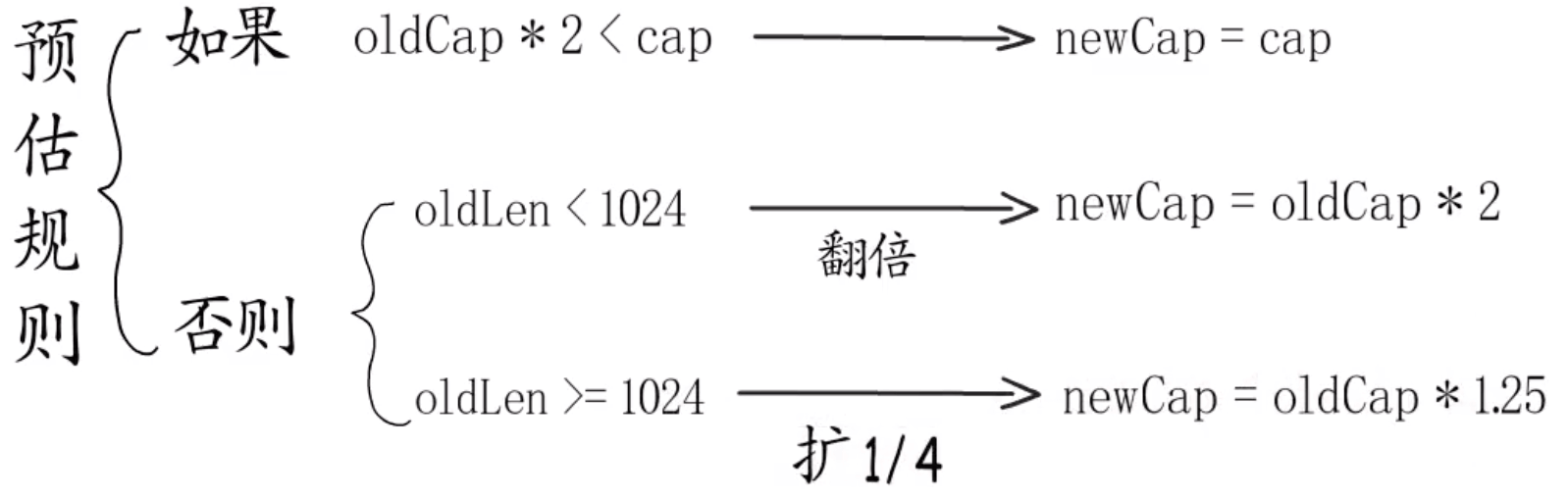
预估容量
内存对齐
第一步,预估新容量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func growslice (et *_type, old slice, cap int ) newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.len < 1024 { newcap = doublecap } else { for 0 < newcap && newcap < cap { newcap += newcap / 4 } if newcap <= 0 { newcap = cap } } } roundupsize... }
预估容量只是预估的元素“个数”。
第二步,内存对齐 内存占用 = 预估容量 * 元素类型大小。
不过,由于 Go 语言的内存分配是由其 runtime 来管理的,程序并不是直接和操作系统打交道。bytes/obj 这列):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package runtime
当程序向 runtime 申请内存时,它会匹配足够大,且最接近的规格。
示例1:元素为int32类型的切片 11_slice_test.go 1 2 3 4 5 6 7 func TestSliceCapGrowthRules1 (t *testing.T) s := []int32 {1 , 2 } t.Log(len (s), cap (s)) s = append (s, 3 , 4 , 5 ) t.Log(len (s), cap (s)) }
11_slice_test.go 1 2 3 4 === RUN TestSliceCapGrowthRules1 11 _slice_test.go :65 : 2 2 11 _slice_test.go :68 : 5 8 --- PASS: TestSliceCapGrowthRules1 (0.00 s)
cap(2 + 3) > doublecap(2 * 2) ,所以预估新容量为5。
int32 占用 4 byte,总内存占用为 5 * 4=20 byte,则 runtime 实际分配的内存为 32 byte,最终的容量为 32 / 4(每个 int 32 占用大小) = 8。
示例2:元素为int64类型的切片 如果将上面例子的 int32 改为 int64,得到的结果会是怎样的呢?
cap(2 + 3) > doublecap(2 * 2),所以预估新容量为5。
int64 占用 8 byte,总内存 5 * 8 = 40 byte,runtime 实际分配 48 byte,48 / 8 = 6。
示例3:append另一个切片 11_slice_test.go 1 2 3 4 5 6 7 8 9 10 func TestSliceCapGrowthRules3 (t *testing.T) a := make ([]int , 20 ) t.Log(len (a), cap (a)) b := make ([]int , 42 ) t.Log(len (b), cap (b)) a = append (a, b...) t.Log(len (a), cap (a)) }
前面z总结过“初始化后的切片,capacity等于len ”,cap(20 + 42) > doublecap(2 * 20),因此预估新容量为62。
由于我是在64位的机器上运行的,因此int为int64,int64占8个字节,所以总内存为 62 * 8 = 496,在内存规格中会选择512,所以新容量为 512 / 8 = 64。
1 2 3 4 5 === RUN TestSliceCapGrowthRules3 11 _slice_test.go :81 : 20 20 11 _slice_test.go :84 : 42 42 11 _slice_test.go :87 : 62 64 --- PASS: TestSliceCapGrowthRules3 (0.00 s)
示例4:元素为string的切片 11_slice_test.go 1 2 3 4 5 6 7 8 9 10 func TestSliceCapGrowthRules4 (t *testing.T) var s string t.Log(unsafe.Sizeof(s)) a := []string {"My" , "name" , "is" } t.Log(len (a), cap (a)) a = append (a, "jason" ) t.Log(len (a), cap (a)) }
cap(3 + 1) < doublecap(2 * 3),因此预估新容量为6。
64位下string占16个字节,总内存为 6 * 16 = 96 byte,匹配到的内存规格为96字节,所以最终扩容后容量为 96 / 16 = 6。
1 2 3 4 5 === RUN TestSliceCapGrowthRules4 11 _slice_test.go :102 : 16 11 _slice_test.go :105 : 3 3 11 _slice_test.go :108 : 4 6 --- PASS: TestSliceCapGrowthRules4 (0.00 s)
总结 graph TB
a[新切片len > 旧切片cap] --> |是|b(扩容)
a --> |否|b1(不扩容)
b --> c[预估新容量newcap]
c --> d{新切片容量最小值 > 2倍旧容量}
d --> |是| e[newcap = 新切片容量最小值]
d --> |否| e1{旧切片长度小于1024}
e1 --> |是| f[newcap = 2倍旧容量]
e1 --> |否| f1[新切片在旧切片容量上每次增长25%直到newcap >= 新切片容量的最小值]
e --> g[内存对齐]
f --> g
f1 --> g
g --> h[预估内存占用 = 预估容量 * 元素类型大小]
h --> i[匹配到runtime申请的内存规格对应的内存]
i --> j[newcap = 匹配到的内存 / 元素类型大小]
classDef mainStep fill:#02d7f2,color:#000
class c,g mainStep
切片共享存储结构 切片是一个共享存储结构 。
11_slice_test.go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func TestSliceShareMemory (t *testing.T) year := []string {"Ja" , "Feb" , "Mar" , "Apr" , "May" , "Jun" , "Jul" , "Aug" , "Sep" , "Oct" , "Nov" , "Dec" } t.Log(year, len (year), cap (year)) summer := year[4 :7 ] t.Log(summer, len (summer), cap (summer)) summer[0 ] = "Unknown" t.Log(summer, len (summer), cap (summer)) t.Log(year, len (year), cap (year)) }
1 2 3 4 5 6 === RUN TestSliceShareMemory 11 _slice_test.go :46 : [Ja Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec] 12 12 11 _slice_test.go :53 : [May Jun Jul] 3 8 11 _slice_test.go :56 : [Unknown Jun Jul] 3 8 11 _slice_test.go :57 : [Ja Feb Mar Apr Unknown Jun Jul Aug Sep Oct Nov Dec] 12 12 --- PASS: TestSliceShareMemory (0.00 s)
通过输出结果可以得知:切片是引用类型 。
数组和切片的区别
容量
数组之间比较
类型
数组
不可伸缩
可比较
值类型
切片
可伸缩
不可比较
引用类型
为了防止篇幅过长,这里只用代码演示下切片的比较,后面我会抽时间具体讲解下。
1 2 3 4 5 6 7 8 9 func TestSliceComparing (t *testing.T) a := []int {1 , 2 , 3 } b := []int {1 , 2 , 3 } }
参考