Linux上统计文件和目录个数命令详解
使用Linux的时候我们经常百度或谷歌搜索命令,其实很多比较长命令我们没必要去死记它,其实你如果把长命令的每个命令分解下,就很容易记住它了。
比如统计目录下文件个数的命令 ls -l | grep "^-" | wc -l ,我们先分析这条命令中各个命令是什么意思,然后再推导出统计目录下目录个数的命令。
ls
ls是一个由POSIX和单一Unix标准规范的命令,在Unix和类Unix系统中都有实现。ls是英文list的缩写,用于列出文件,是Unix和类Unix系统中使用非常频繁的命令。
语法
1 | ls [-ABCFGHLOPRSTUW@abcdefghiklmnopqrstuwx1] [file ...] |
不加参数时
当不加参数运行时,ls列出当前目录下的除隐藏文件外的所有文件和目录名。
不加参数时,ls仅仅列出文件和目录的名称,不加任何修饰。这通常让人很难区分文件的类型、大小、权限等属性。
以目录名为参数
如果以目录名作为参数,则会列出该目录下的文件。用户也可以指定多个文件和目录作为参数,ls则会列出所有指定的文件和目录中的文件名。
加
-a参数才能显示隐藏文件
如以 “.”(圆点)开头的目录在一般情况下不会被列出。用户可以加-a选项查看所有文件。
常用参数
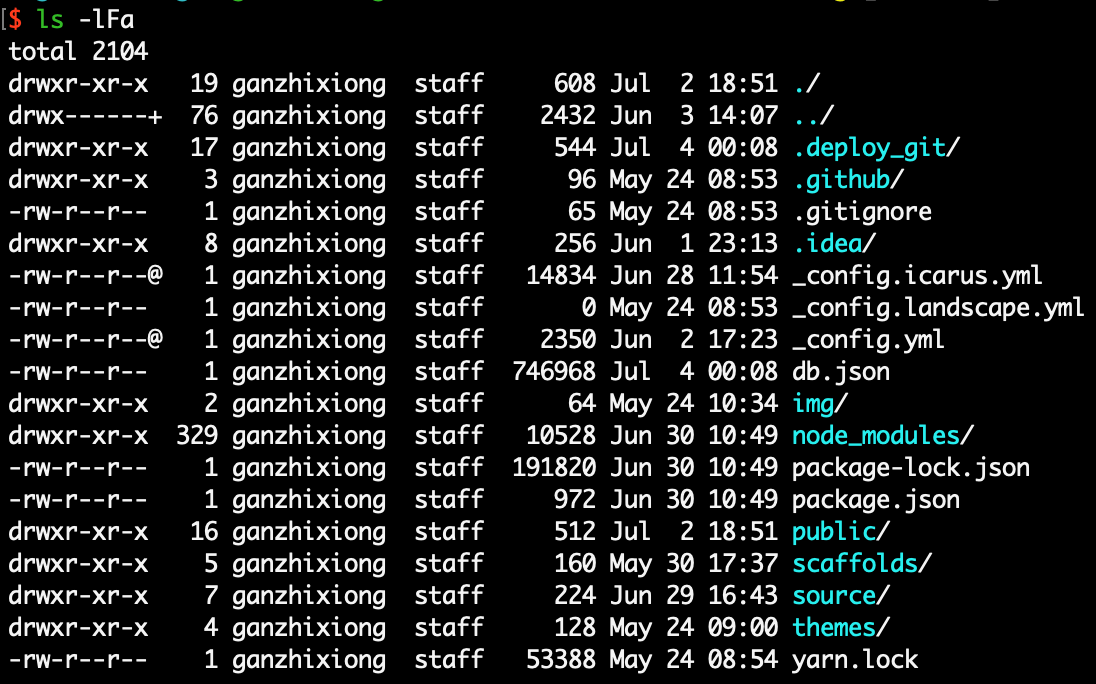
-l(long)长格式,显示文件类型、权限、硬链接的数目、文件拥有者、文件所在的组、大小、日期和文件名。-F在不同类型的文件的文件名结尾追加一个字符以示区别。可执行文件后加”*”,目录后加”/“,管道文件后加”|”,套接字文件后加”=”,普通文件没有后缀。-a(all)显示所有文件,包括以 . 开头的文件名(默认不显示)。-A(all)显示所有文件,不包括以.(自身目录)和..(父目录)。相关词条:Inode-R(recursive)迭代显示目录下所有的子目录。ls -R/会显示文件系统中的所有文件。-d(directory)显示目录本身的信息,而不是列出目录下的文件。
l或ll
有的系统直接输入l或ll也可以显示类似ls的效果。
但是想查询 l或ll 命令使用方法,却查询不到:
原来 l或ll 是被定义好的别名(alias),别名就是赋予一条命令或者一列命令的名称。
通过 alias 命令可以查询别名的具体命令,如: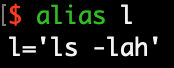
查看全部别名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ alias
-='cd -'
...=../..
....=../../..
.....=../../../..
......=../../../../..
1='cd -'
2='cd -2'
3='cd -3'
4='cd -4'
5='cd -5'
6='cd -6'
7='cd -7'
8='cd -8'
9='cd -9'
_=sudo
afind='ack -il'
d='dirs -v | head -10'
g=git
ga='git add'自定义别名
1
vim ~/.bashrc
管道
管道命令的形式是“命令1 | 命令2”,其中命令2是管道命令。
管道命令可以是查找字符串的grep命令,也可以sort这样的排序命令,也可以是wc这样的统计命令,anyway,无论是查找还是排序,抑或是统计,他们操作的对象是命令1输出的一行一行字符串。
grep
grep是一个最初用于Unix操作系统的命令行工具。在给出文件列表或标准输入后,grep会对匹配一个或多个正则表达式的文本进行搜索,并只输出匹配(或者不匹配)的行或文本。
grep这个应用程序最早由肯·汤普逊写成。grep原先是ed下的一个应用程序,名称来自于g/re/p(globally search a regular expression and print,以正则表达式进行全局查找以及打印)。在ed下,输入g/re/p这个命令后,会将所有符合先定义样式的字符串,以行为单位打印出来。
参数
-i或--ignore-case忽略大小写。-v或--invert-match不显示不包括匹配文本的所有行。
列出文本中包含“hexo”的文本行

grep默认情况下是大小写敏感的,因此不会返回匹配“Hexo”的文本行。
通过 -i 参数则可以忽略大小写:
1 | grep -i hexo package.json |
列出文本中以“d”开头的文本行
1 | $ grep '^d' .gitignore |
正则表达式
^表示行首, “d$” 表示行首以d开头的文本行。$表示行尾, “d$” 表示行尾以d开头的文本行。注意$符号的位置。-
[^]匹配除 [^字符] 之外的任何一个字符。 例如9[^0], 不会匹配90,但是会匹配91,92等。
wc
**wc** (英语:word count)是在类UNIX操作系统中的一个命令。
程序从标准输入流或文件列表读取文件,并生成一个或多个下列统计信息: 文件包含的字节数、单词数以及文件的行数(也就是换行符的个数)。如果用户提供的是一个文件列表,则每个文件的单独统计和总体统计结果都会给出。
wc程序示例:
1 | $ wc foo bar |
第一列表示文件中的行数,以上实例表示文本文件foo有40行,并且bar文件包含2294行,总计2334行。 第二列表示文件中的单词个数:foo文件包含149个单词,且bar文件中有16638个单词,总计16787个单词。 第三列表示文件中包含的字符个数:foo文件总共有947个字符,且bar文件中有97724个字符,总计有98761个字符。
较新版本的wc可以区别比特和字符的统计。区别在于:Unicode字符集包含了多字节的字符。可以通过选择 -c 或是 -m 参数来选择所需的行为。
语法
1 | wc [-clmw] [file ...] |
参数
wc -l <文件名>输出行数统计wc -c <文件名>输出字节数统计wc -m <文件名>输出字符数统计wc -L <文件名>输出文件中最长一行的长度wc -w <文件名>输出单词数统计
获取目录中文件和目录数量
1 | ls -A | wc -l |
获取目录中文件数量
- 方法一,匹配行首以
-开头的文本行
1 | ls -lA | grep "^-" | wc -l |
- 方法二,匹配行尾不以
/结尾的文本行
1 | ls -AF | grep -v '/$' | wc -l |
- 方法三,匹配行尾除了以
/结尾的文本行
1 | ls -AF | grep '[^/]$' | wc -l |
获取目录中的目录数量
- 方法一,匹配行首以
d开头的文本行
1 | ls -lA | grep '^d' | wc -l |
- 方法二,匹配行尾以
/结尾的文本行
1 | ls -AF | grep '/$' | wc -l |
- 方法三,匹配行尾以
/结尾的文本行
1 | ls -AF | grep -v '[^/]$' | wc -l |
Linux上统计文件和目录个数命令详解

